Tools & Platforms Mentioned
Logos are loaded from a lightweight icon CDN. If any are blocked by your network, the text labels will still display.
 OpenAI
OpenAI
 Anthropic
Anthropic
 Adobe
Adobe
 Microsoft
Microsoft
 ElevenLabs
ElevenLabs
 Google
Google
Textbook-style chapter compiled from provided course materials. Where “Editorial additions” appear, they are clearly labeled.
Logos are loaded from a lightweight icon CDN. If any are blocked by your network, the text labels will still display.
OpenAI
Anthropic
Adobe
Microsoft
ElevenLabs
Google
Module objectives (from the Course Guide):
Key terms (from this module’s content):
ELIZA; rule-based chatbot; keyword detection; natural language processing (NLP); machine learning (ML); conversational agent; transformer; large language model (LLM); generative AI; reasoning model; chain-of-thought prompting; hallucination; tokens; latency; context length; ASR; TTS; NLU; voice biometrics; GAN; diffusion model; self-attention; multimodal models; fine-tuning; DreamBooth; LoRA; APIs; compliance (GDPR/CCPA/HIPAA/LGPD).
This module is written for leaders who need “working fluency”—enough depth to make responsible strategic decisions, ask better questions, and evaluate trade-offs without becoming a specialist.
This module positions generative AI as a practical capability—systems that can produce text, images, audio, and more— and links those capabilities to organizational performance and digital transformation. The later sections unpack how we arrived here (chatbots), what makes AI expensive (cost drivers), and how new modalities (audio and images) reshape workflows.
The Course Guide lists “Generative AI Fundamentals” as Section 1 of Module 1. The provided Module 1 text begins with chatbot evolution and then expands into cost, multimedia, and advanced tools. This short orientation connects the given content to the official outline.
Chatbot capabilities have evolved significantly since MIT professor Joseph Weizenbaum created ELIZA, the world’s first chatbot, in 1966. Early systems were rule-based: they detected keywords and returned pre-scripted responses. These systems lacked NLP capabilities and were limited in scope and output (Murphy, 2023).
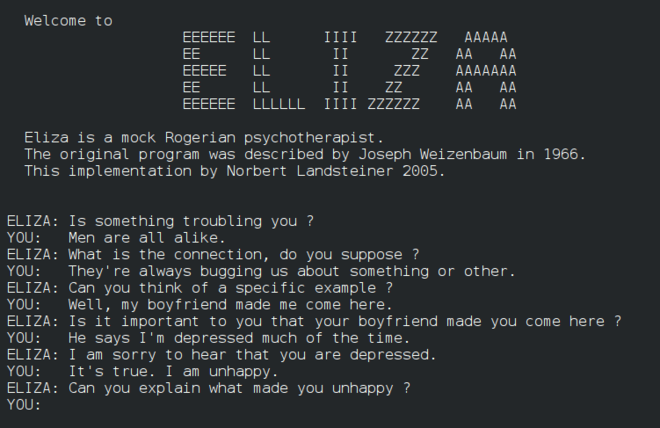
In the early 2010s, machine learning (ML) advancements enabled a new generation of chatbots—conversational agents— that better understood natural language and could complete more complex tasks (Murphy, 2023). Examples include IBM Watson, Siri, and Alexa. Developments in the late 2010s—transformer-based neural networks and large language models (LLMs)—paved the way for generative AI chatbots that can handle larger query volumes and deliver more personalized, natural-sounding responses (Marr, 2024).

Reasoning models (e.g., OpenAI’s o3 and o4 models) represent a more recent milestone. These models are trained to spend more time processing queries, “thinking through” problems before responding, like a human analyst would (Williams, 2025). They have demonstrated improvements on tasks requiring complex reasoning in areas such as science, coding, and math (Paul & Tong, 2024).
Chain-of-thought prompting is designed to improve the ability of LLMs to perform complex reasoning. It involves generating intermediate natural language reasoning steps that lead to a final answer, simulating a human-like thought process.
Example (from module content): For “Market A vs. Market B,” a chain-of-thought-enabled model would analyze factors separately—market size, competition, regulatory environment—before recommending a direction.
The module notes that hallucination remains an inherent risk of LLMs: models may generate outputs not grounded in training data or recognized patterns, producing false or inaccurate claims. The module also notes an OpenAI study in which o4-mini hallucinated more than earlier ChatGPT models on certain metrics.
Unlike traditional chatbots that primarily react to prompts, agentic AI can take action autonomously and proactively, adapt to context, and execute goals in complex environments with minimal human intervention (Coshow et al., 2025). According to MIT’s Dr. Abel Sanchez, an AI agent is essentially a workflow with tasks that may involve humans.
Illustrative use cases (from module content):
The module argues that customer-facing chatbots now handle more queries with higher accuracy and nuance, and can offer increasingly personalized responses based on customer data and prior interactions (Marr, 2024). It also suggests that AI customer-experience agents may allow organizations to automate a significant share of customer interactions while boosting engagement (Coshow et al., 2025).
In 2024, Klarna adopted an AI customer service assistant powered by OpenAI. The chatbot reportedly handled a workload equivalent to 700 full-time agents in its first month. Repeat inquiries fell by 25%, and the average service time was two minutes versus 11 minutes with human agents.
Octopus Energy integrated ChatGPT into its customer service channel and assigned responsibility for handling inquiries. According to the company, the system handles the work of 250 people and has received higher average customer satisfaction ratings than human agents.
As organizations deploy AI at scale, cost and performance become strategic constraints. Choosing the most powerful model may be economically unsustainable, while prioritizing low cost alone may limit system utility. This section explains what drives cost and how to think about trade-offs in real deployments.
A premium minivan is great for driving your kids to school, but absurd if you must get every kid in a town to school. At scale, you choose buses, bike convoys, or walking groups. Similarly, “best” AI is not always the most powerful model—it’s the best fit for the task under constraints.
The module highlights tokens as a major cost driver for LLM usage. Tokens are units of text (often ~3–4 characters). Both input and output are measured in tokens and priced accordingly (OpenAI, 2023, as cited in the module content).
The module provides an example interaction with 500 input tokens and 1,000 output tokens at $0.03/1k input and $0.06/1k output. The exact cost is: (0.5 × $0.03) + (1.0 × $0.06) = $0.015 + $0.06 = $0.075 per interaction. This corrects arithmetic only; the strategic point (cost compounding at scale) remains the same.

The module frames deployment as trade-offs across:
Audio and language interaction can sound simple, but they require complex technical architectures. This section distinguishes core components (ASR, TTS, NLU, voice biometrics), common combinations across industries, and operational cost drivers such as real-time constraints and customization.
| Technology | Definition | Common uses |
|---|---|---|
| ASR (Automatic Speech Recognition) | Converts spoken language into text | Transcription, captioning, command processing |
| TTS (Text-to-Speech) | Converts text into natural-sounding speech | Voice assistants, voiceovers, news readers |
| NLU (Natural Language Understanding) | Determines intent and context from language | Voice-based customer service, conversational agents |
| Voice biometrics | Uses unique voice characteristics for authentication | Fintech, healthcare, high-security environments |

| Sector | Use case | Typical stack (as provided) |
|---|---|---|
| Healthcare | Dictation, transcription, patient interaction | Whisper + NLP layer (HIPAA compliance needed) (Paubox, 2025) |
| Retail | Voice-based customer service kiosks | TTS + ASR + chatbot NLU (PYMNTS, 2024) |
| Education | Language learning, accessibility, lectures | TTS (multilingual) + voice grading (Wood et al., 2018) |
| Finance | Call center automation, sentiment analysis | ASR + NLU + analytics (Grace, 2025) |
| Automotive | In-car voice assistants | Edge-optimized ASR + embedded NLU (EE Times, 2025) |
| Risk | Example | Mitigation |
|---|---|---|
| Unconsented recording | Recording user voices without notification | Explicit consent prompts and audio cues |
| Data retention | Storing audio indefinitely | Strict retention policies; allow deletion |
| Biometric misuse | Using voiceprints without explicit consent | Require opt-in for voice biometrics |
| Third-party leakage | Sending user data to cloud APIs unsafely | Strong contracts (DPAs) or on-prem storage |
| Cross-border transfer | Using U.S. servers for EU users | Comply with international transfer agreements (SCCs, DPF) |
This section shifts from broad technology categories to practical toolsets: image generation, audio generation, text generation, and video generation. It also explains why hybrid architectures (GANs + diffusion + transformers) are common in real products and why agentic AI is positioned as the next wave.
| Capability | Use cases (as provided) |
|---|---|
| Image generation | Campaign visuals; product mockups; concept art; training illustrations; infographics |
| Audio generation | Voice agents/IVR; accessibility; language learning; audiobooks/podcast narration |
| Text generation | Email drafting; chatbot scripts/FAQs; reports and summarization; documentation and SOPs; SEO content |
| Video generation | Short-form ads; explainer videos; video lessons; concept trailers and storyboards |
The module emphasizes that these systems are increasingly used in combination: GANs for speed/realism, diffusion for diversity/stability, and transformers for coherence and control—sometimes within the same application.
| Level | Description | Example tools | Best for | Trade-offs |
|---|---|---|---|---|
| Off-the-shelf APIs | Hosted models via API; no setup; pay-per-use | DALL·E 3 (OpenAI API), DreamStudio, Adobe Firefly | Quick prototypes, marketing images, general needs | Limited fine-tuning; pay per call; possible data lock-in |
| Open-source local models | Install models on your own servers/private cloud | Stable Diffusion (base/XL), HuggingFace Diffusers | More control, privacy, brand consistency | Setup + compute cost; requires in-house expertise |
| Custom fine-tuned models | Train a model on proprietary style/data | DreamBooth, LoRA, custom SD forks | High-volume brand-specific content | Expensive training + ongoing maintenance |
Thus far in this module, we have explored the foundational principles of AI, generative AI, and agentic AI—tracing the field from its early origins to its current, market-disrupting capabilities. We have also examined how written, audio, and visual technologies each contribute to the evolving AI landscape.
This final section shifts from broad technology categories to a more practical view: the specific tools and platforms that organizations can use to integrate AI functionality into real workflows and improve performance.
The module categorizes widely used tools by the type of content they generate—images, audio, text, and video. This “toolbox” view helps leaders translate AI capabilities into concrete business applications.
Definition (from module framing): AI tools that generate images from text prompts or other inputs, enabling rapid content creation at scale.
Use cases (from module content):
Use cases (from module content):
Use cases (from module content):
Use cases (from module content):
Generative AI is already reshaping how organizations create text, audio, and visual content. The next frontier is agentic AI—systems that do not just respond to commands but take initiative, make decisions, and coordinate across tools autonomously. In the next module, the course explores how this evolution opens new possibilities for automation, personalization, and digital intelligence at scale.
The following questions are designed to help learners consolidate Module 1 concepts. They are not presented as original course content.
Assignment listed in Course Guide: “Assignment 1: Evaluating the Cost of AI Systems.”
Since only the assignment title is provided, the following is a suggested template to help students apply Section 3’s concepts without inventing course requirements. Adapt as needed to match your facilitator’s instructions.
This list preserves the references exactly as they appear in the provided Module 1 content. Full bibliographic details can be added if you provide them.